在当今数据驱动的时代,企业面临着对海量数据进行高效批处理和近实时分析的巨大挑战。传统的数据架构往往将批处理与流处理割裂,导致数据孤岛、处理延迟和运维复杂。Apache Hudi(Hadoop Upserts Deletes and Incrementals)应运而生,它作为一个开源的数据湖框架,旨在通过统一的数据存储与服务层,弥合批处理与流处理之间的鸿沟,提供增量数据处理、高效的更新删除以及近实时的数据可见性。
一、Hudi 的核心设计理念:统一存储与服务
Hudi 的核心价值在于其“统一”的特性。它并非取代现有的批处理(如 Apache Spark)或流处理(如 Apache Flink)计算引擎,而是作为其下的一个存储与服务层,为上层应用提供一致、高效的数据管理能力。其设计目标包括:
- 增量处理:支持对数据湖进行记录级的插入、更新和删除,避免传统批处理中全量覆盖的低效操作。
- 近实时摄取:允许数据以分钟甚至秒级的延迟被写入并立即对查询可见。
- 统一视图:为批处理作业和交互式查询提供同一份数据的统一视图,确保数据一致性。
- 事务保障:提供了写入和快照隔离级别的读取,确保并发操作下的数据准确性。
二、关键技术特性:实现批流一体的基石
Hudi 通过一系列创新特性,实现了对批处理和近实时分析场景的统一支持:
- 表类型与查询类型:
- Copy-on-Write (CoW) 表:在写入时直接合并新数据到列存文件(如 Parquet),适合读多写少、追求最佳查询性能的场景。批处理和快照查询直接读取最新的数据文件。
- Merge-on-Read (MoR) 表:写入时将更新数据存入行存日志文件(如 Avro),后台异步或按需合并到列存文件。这极大地优化了写入延迟,特别适合写多读少或需要极低延迟数据可见性的近实时场景。查询时,实时读取会合并列存文件和日志文件以提供最新快照。
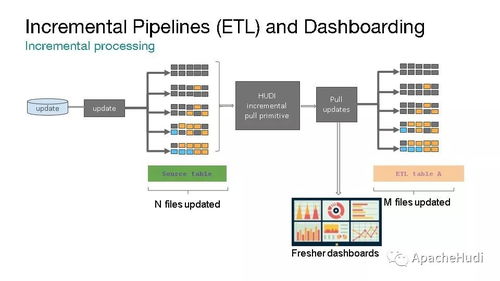
- 增量查询:这是 Hudi 的杀手锏功能。它允许用户从某个时间点或提交点开始,仅查询新写入或更改的数据,而非全表扫描。这对于构建增量 ETL 管道、同步数据到外部系统或进行近实时监控至关重要。
- 自动文件管理:Hudi 自动管理文件大小、执行压缩(Compaction,将 MoR 表的日志文件合并到列存文件)和清理(Cleanup,删除旧版本文件),优化存储布局和查询性能。
- 索引机制:Hudi 内置了多种索引(如布隆过滤器索引、HBase索引),用于在 Upsert/Delete 操作时快速定位目标数据所在文件,避免全表扫描,提升写入效率。
三、数据处理与存储服务:Hudi 的实际应用
在数据处理与存储服务层面,Hudi 扮演着核心枢纽的角色:
- 数据摄取服务:
- 批量数据入湖:传统的 T+1 批量数据可以通过 Spark 作业高效地以 Upsert 方式写入 Hudi,避免重复和覆盖问题。
- 近实时流式摄取:来自 Kafka 等消息队列的流数据,可以通过 Spark Structured Streaming、Flink 等引擎持续写入 MoR 表,实现分钟级甚至秒级延迟的数据入湖,并立即可查。
- 数据存储与管理服务:
- 高效的更新与删除:满足 GDPR “被遗忘权”等合规要求,或处理业务数据变更,Hudi 支持对海量数据湖进行记录级更新和删除。
- 时间旅行与版本回溯:Hudi 保留了数据的历史版本,用户可以查询任意时间点的数据快照,便于审计、调试和恢复。
- 存储优化:通过自动的压缩和聚类(Clustering)服务,优化文件大小和数据布局,提升查询性能。
- 数据服务与消费:
- 统一查询服务:无论是 Presto、Trino、Spark SQL 进行的交互式分析,还是 Hive 进行的批处理报表,都可以基于同一张 Hudi 表进行,获取一致的最新数据视图。增量查询功能则专门服务于下游的增量同步和近实时分析应用。
- 近实时分析:数据工程师和分析师可以基于 MoR 表的实时视图,对刚刚入湖的数据进行即时查询和分析,快速响应业务变化。
四、架构优势与未来展望
采用 Apache Hudi 构建数据湖存储层,为企业带来了显著优势:简化了数据架构,降低了批流融合的复杂性;提升了数据新鲜度和处理效率;同时保证了数据的完整性和一致性。
随着云原生和湖仓一体(Lakehouse)架构的兴起,Hudi 正持续演进,更好地与云存储(如 AWS S3)、计算引擎以及数据治理工具集成。它正成为构建现代化、高性能、可扩展的数据平台的关键组件,助力企业在统一的存储与服务基础上,实现从传统批处理到智能实时分析的平滑演进。
总而言之,Apache Hudi 不仅仅是一个存储格式,更是一个功能强大的数据湖存储与服务引擎。它通过统一批处理和近实时分析的数据存储层,为高效、可靠、敏捷的数据处理流水线奠定了坚实的基础。