随着企业数据规模的爆炸式增长和业务对实时性、敏捷性要求的不断提升,传统的Hadoop架构因其紧耦合的存算一体模式,在资源弹性、运维成本和技术演进上面临着显著挑战。在此背景下,以Hadoop存算分离为基础,构建云原生数据存储管理与数据处理服务,已成为大数据平台现代化演进的核心路径。本文将深入解析这一架构的核心理念、关键技术与实现方案。
一、 从存算一体到存算分离:架构演进的内在逻辑
传统Hadoop(以HDFS + YARN + MapReduce/Spark为代表)将存储(HDFS)与计算(计算框架)深度绑定在同一批物理节点上。这种设计在早期带来了数据本地性优势,减少了网络传输开销。但随着云计算的普及和业务需求的变化,其弊端日益凸显:
- 资源利用不均:存储和计算资源无法独立扩展,容易造成一方资源闲置而另一方资源紧张。
- 弹性能力不足:扩容或缩容需同时调整存储和计算节点,流程复杂,无法快速响应业务波动。
- 成本高昂:为满足峰值计算需求,往往需要过度配置存储资源,导致总体拥有成本(TCO)上升。
- 技术栈锁死:计算引擎与HDFS强绑定,难以灵活引入新的数据处理框架或对象存储等新型存储。
存算分离的核心思想正是解耦存储与计算。存储层采用独立、可扩展的分布式存储服务(如对象存储、云原生分布式文件系统),计算层则变为无状态的、可按需弹性伸缩的容器化集群。两者通过高速网络连接,计算层按需访问远端统一的数据湖存储。
二、 Hadoop存算分离的云原生实现路径
实现Hadoop生态的存算分离,并非简单替换HDFS,而是一个系统性工程,主要涉及以下层面:
1. 存储层云原生化:构建统一数据湖存储
- 存储选型:采用与云环境深度集成的对象存储服务(如AWS S3、Azure Blob Storage、阿里云OSS、华为云OBS)或兼容S3协议的分布式文件系统(如Ceph、MinIO)。这些服务提供近乎无限的扩展能力、高耐久性和按使用量付费的模式。
- 数据组织与元数据管理:虽然原始数据存储在对象存储中,但目录结构、文件权限、事务支持等“类文件系统”的元数据管理仍需解决。常用方案包括:
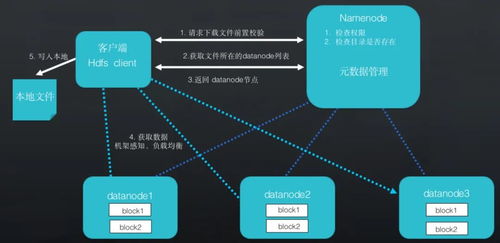
- 使用HDFS Namenode的优化版本:如腾讯云COSN、阿里云JindoFS、华为云OBS-FS,它们通过实现HDFS文件系统接口,将元数据与数据分离,元数据由独立服务管理,数据则落地对象存储。
- 采用Lakehouse架构的元数据层:如Apache Hudi、Delta Lake、Apache Iceberg。它们在对象存储之上构建了具有ACID事务、版本管理、高效Upsert/Delete能力的表格式层,成为连接计算引擎与底层存储的“智能中间层”,是实现存算分离和高级数据管理的关键。
2. 计算层容器化与弹性化
- 计算框架适配:主流计算引擎(如Spark、Flink、Presto/Trino、Hive)均已支持直接读写对象存储(通过
S3A、OSS等连接器)或上述表格式。任务运行时从对象存储拉取数据。
- 资源管理与调度云原生化:放弃YARN,转而使用Kubernetes作为统一的容器编排与资源调度平台。计算任务(Spark Job、Flink Session等)被封装为Kubernetes Pod,由K8s负责其生命周期管理、资源调度、弹性伸缩(HPA/VPA)和高可用保障。这实现了极致的计算资源弹性和运维自动化。
3. 数据访问与缓存加速
网络延迟是存算分离的主要顾虑。为保障性能,需构建多层次缓存体系:
- 计算侧本地缓存:Spark/Flink等任务在计算节点本地SSD或内存中缓存热数据块。
- 分布式缓存层:部署独立的分布式缓存集群(如Alluxio、JindoFS缓存模式),作为计算集群与对象存储之间的透明加速层。它能聚合计算节点的内存和SSD,提供POSIX或HDFS接口,对热数据进行集中缓存和智能预取,显著降低访问延迟和对象存储的出口带宽成本。
三、 实现云原生数据存储管理与数据处理服务
基于上述架构,可以构建一个完整的云原生数据平台服务:
- 统一的数据湖存储服务:对象存储作为企业数据的单一可信来源,承载原始数据、清洗后数据、模型数据等。结合Delta Lake/Iceberg等表格式,提供数据版本、模式演进、时间旅行、增量更新等企业级数据管理能力。
- 弹性的数据处理服务:
- 按需启停的计算集群:数据处理任务(ETL、流处理、即席查询)以容器化方式运行在K8s上,任务完成后资源立即释放,实现“零闲置成本”。
- Serverless交互式查询:利用Presto/Trino on K8s,配合资源自动伸缩,为用户提供秒级启动、按查询付费的交互式分析服务。
- 统一的工作流编排:使用Airflow、Kubeflow Pipelines等云原生友好的工具进行任务编排和MLOps管理,所有任务均调度到K8s集群执行。
- 智能的数据治理与安全:在云原生环境下,可集成统一的权限管理(如Ranger、AWS IAM)、数据血缘、质量监控和成本分析工具,实现跨存储和计算资源的精细化管控。
四、 优势与挑战
优势:
- 极致弹性与敏捷性:存储与计算独立无限扩展,计算资源秒级伸缩,快速响应业务。
- 显著降低成本:存储采用低成本高耐久的对象存储,计算按实际使用量付费,资源利用率大幅提升。
- 技术开放与创新:计算引擎与底层存储解耦,便于引入新技术栈,避免供应商锁定。
- 运维简化:依托云平台和K8s的自动化运维能力,降低了集群管理的复杂性。
挑战与考量:
- 网络性能与成本:需优化网络架构(如使用VPC内网、高速通道)并合理设计缓存策略,以平衡延迟与成本。
- 数据一致性语义:对象存储的“最终一致性”模型与HDFS的“强一致性”存在差异,需通过表格式层或客户端适配来满足业务要求。
- 生态工具适配:部分传统Hadoop生态工具(如某些旧版本的Sqoop、特定依赖HDFS API的应用)需要改造或替换。
###
Hadoop存算分离并迈向云原生,是大数据平台应对云时代挑战的必然选择。它并非颠覆Hadoop生态,而是对其核心价值的继承与升华——将Hadoop丰富的计算生态与云原生的弹性、敏捷和成本优势相结合。通过采用对象存储、容器化计算、智能数据湖格式及缓存加速等技术,企业能够构建一个存储无限扩展、计算瞬时可得、管理智能统一的现代化数据平台,从而更好地赋能数据驱动业务创新。