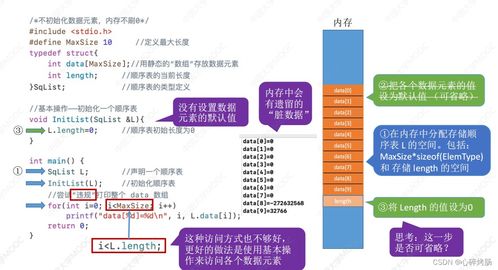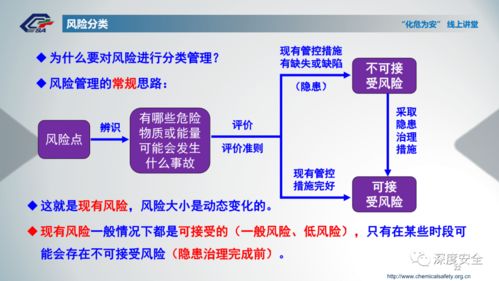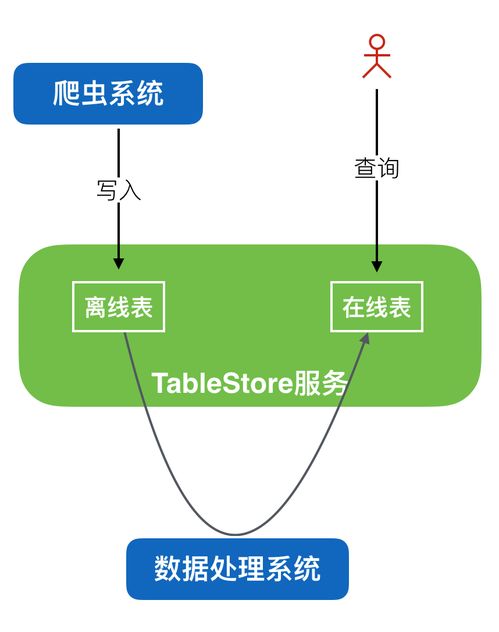
在人工智能浪潮席卷全球的今天,深度学习模型的开发与训练已成为推动技术进步的核心驱动力。从海量数据中提取价值、构建并迭代复杂模型的过程,往往伴随着巨大的计算资源消耗、繁琐的运维管理和数据处理的复杂性。为了应对这些挑战,业界领先的深度学习框架 PaddlePaddle(飞桨) 与云原生容器编排领域的王者 Kubernetes(K8s) 展开了深度协同,共同为开发者打造了一套高效、弹性、可扩展的模型训练与数据处理解决方案,显著降低了AI应用落地的门槛。
一、强强联合:PaddlePaddle 与 Kubernetes 的协同优势
PaddlePaddle 作为百度开源、国内首个自主研发的产业级深度学习平台,以其开发便捷的框架、丰富的模型库、高效的分布式训练能力和端到端的部署工具链而闻名。它旨在让开发者能够更轻松地将创意转化为实际应用。
Kubernetes 则是一个开源的容器编排系统,它自动化了容器化应用程序的部署、扩展和管理。其核心价值在于提供了强大的资源调度、服务发现、弹性伸缩和故障恢复能力,确保应用能够稳定、高效地运行在复杂的集群环境中。
当 PaddlePaddle 的深度学习能力与 Kubernetes 的云原生基础设施管理能力相结合,便产生了奇妙的化学反应:
- 资源利用最大化:Kubernetes 可以智能调度 PaddlePaddle 训练任务到集群中最合适的计算节点(如GPU服务器),实现CPU、内存、GPU等资源的精细化管理和高效利用,避免资源闲置或争抢。
- 训练任务弹性伸缩:面对不同规模的数据集和模型,开发者可以轻松地通过 Kubernetes 动态调整训练任务的并行度(Worker数量)。无论是需要启动上百个节点的超大规模分布式训练,还是临时增加资源以加速实验,都能一键完成,极具弹性。
- 简化运维与高可用:Kubernetes 自动管理训练任务的生命周期,包括自动重启失败的任务、健康检查、滚动更新等。开发者无需再手动监控和管理每一个训练进程,可以将精力集中于算法和模型本身。
- 标准化与可移植性:容器化将 PaddlePaddle 的运行环境、依赖库和代码打包成一个标准镜像。结合 Kubernetes,这套训练流水线可以在任何支持 K8s 的云环境或私有数据中心中无缝运行,实现了“一次构建,随处运行”。
二、核心助力:高效训练与数据处理存储服务
本次联手对开发者的助力,核心体现在两个紧密相关的环节:模型训练 与 数据处理/存储。
高效模型训练服务
通过 PaddlePaddle 的分布式训练能力(如 Fleet API)与 Kubernetes 的编排能力深度集成,可以实现:
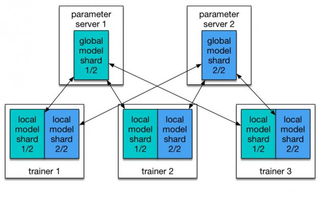
- 一键式分布式训练:开发者只需定义好训练任务和所需的资源规格,Kubernetes 即可自动创建和管理一组训练 Pod(容器组),其中包括参数服务器和多个训练工作节点,快速启动大规模分布式训练。
- 混合调度与异构计算:Kubernetes 可以调度任务到混合架构的集群(如不同型号的GPU、CPU机器),PaddlePaddle 能够利用这些异构资源进行训练,提供了极大的灵活性。
- 实验管理与流水线:结合 Kubeflow 等基于 K8s 的 MLOps 工具,可以构建完整的机器学习流水线,实现从数据预处理、模型训练、超参调优到模型评估的自动化,极大提升团队协作效率和实验可复现性。
统一的数据处理与存储服务
模型训练的效率严重依赖于数据供给的“管道”。PaddlePaddle 与 Kubernetes 生态的结合,为数据层提供了强大支持:
- 持久化存储集成:Kubernetes 支持多种持久卷(Persistent Volume)类型,如网络存储(NFS、Ceph、云盘等)。训练任务可以轻松挂载这些存储卷,实现训练数据的集中式、高可用存储,数据在任务销毁后依然保留。
- 高性能缓存与加速:对于超大规模数据集,可以结合 Alluxio、Fluid 等云原生数据编排系统,在计算集群内部构建分布式缓存层,将远程存储的数据缓存在本地或高速 SSD 上,为 PaddlePaddle 训练任务提供内存级的数据访问速度,彻底消除 I/O 瓶颈。
- 数据预处理容器化:将数据清洗、增强、格式转换等预处理步骤也封装为容器化任务,在 Kubernetes 上作为训练流水线的一个前置步骤运行。这使得复杂的数据处理流程也能享受资源的弹性调度和标准化的管理。
- 统一数据访问接口:无论数据存放在对象存储、HDFS 还是本地,通过相应的 CSI 驱动或客户端库,PaddlePaddle 训练程序都能以近乎一致的方式进行访问,简化了代码复杂度。
三、开发者体验与未来展望
对于开发者而言,这种集成意味着他们可以从繁琐的基础设施管理中解放出来,获得一个“唾手可得”的、企业级的 AI 研发平台。他们能够:
- 更快地开始实验:通过预制的容器镜像和 Kubernetes 部署清单,快速搭建训练环境。
- 更放心地运行长时任务:依托 K8s 的稳定性,安心进行长达数天甚至数周的模型训练。
- 更高效地利用资源:按需申请计算资源,按量计费,显著降低研发成本。
- 更顺畅地协同与交付:标准化的环境使得模型从研发到生产部署的路径更加顺畅。
随着 PaddlePaddle 的持续演进和 Kubernetes 生态的日益繁荣,两者的结合将更加紧密。我们有望看到更多开箱即用的 Operator(例如 PaddlePaddle Operator)来进一步简化部署,更智能的自动扩缩容策略,以及与边缘计算场景的深度融合,为 AI 技术在千行百业的落地提供无处不在的强劲算力和数据服务支撑。
PaddlePaddle 与 Kubernetes 的联手,不仅是技术的融合,更是为 AI 开发者构建了一条通往高效生产力和创新成功的“高速公路”。它正推动着深度学习模型的开发从手工作坊模式,迈向标准化、自动化、规模化的工业级生产新时代。